Different request and response serializers in Django REST Framework
Django REST Framework can be a very productive framework for writing HTTP endpoints based on Django models. At first glance, it seems to support just about everything you might want in a typical HTTP API. However, having different request and response (or read and write) serializers for ModelViewSets is not one of them.
The problem with ModelViewSets and multiple serializers
Of course, one can go and write completely custom APIViews and use any serializers for inputs and outputs without any problems. But if we want to get the most out of Django REST Framework (DRF) we might prefer to use ModelViewSets, at least at the beginning, to create endpoints faster and with less code.
The problem is that a typical implementation of ModelViewSet lets us specify just one serializer:
from rest_framework.viewsets import ModelViewSet
from .models import Project
from .serializers import ProjectSerializer
class ProjectViewSet(ModelViewSet):
queryset = Project.objects.all()
serializer_class = ProjectSerializer
But don’t despair. As with just about anything, DRF has a get_serializer_class hook that can be used to provide the desired serializer dynamically. REVSYS has an article on using different read and write serializers that would alter the behavior in the following fashion:
from rest_framework.viewsets import ModelViewSet
from .models import Project
from .serializers import ProjectReadSerializer, ProjectWriteSerializer
class ProjectViewSet(ModelViewSet):
queryset = Project.objects.all()
read_serializer_class = ProjectReadSerializer
write_serializer_class = ProjectWriteSerializer
def get_serializer_class(self):
if self.action in ["create", "update", "partial_update", "destroy"]:
return self.get_write_serializer_class()
return self.get_read_serializer_class()
This approach works well when it is enough to have different serializers based on actions.
So you might ask, what is the problem then?
I wanted to have different read and write serializers even for the actions themselves. A true pair of request and response serializers so that even an action like create would use one serializer for the POST request and another one for producing the response. That means that if an API client creates a resource, it can get back information about it that would otherwise need to be fetched by a separate request.
It turns out that it is possible to do so. The solution is to delegate the responsibility of generating the output of one serializer to another. We can even document endpoints that use such serializers properly using drf-spectacular, the common OpenAPI spec generator for Django REST Framework. Before we proceed, let’s define our models to illustrate how it all works.
Models
Imagine that we have two models: Workspace and Project where each project belongs to one workspace. They will both also have a reference to the user that created them:
from django.db import models
from .models import User
class Workspace(models.Model):
name = models.CharField(blank=False, null=False, max_length=200)
created_by = models.ForeignKey(User, null=True, on_delete=models.SET_NULL)
def __str__(self):
return self.name
class Project(models.Model):
name = models.CharField(blank=False, null=False, max_length=200)
workspace = models.ForeignKey(Workspace, on_delete=models.CASCADE)
created_by = models.ForeignKey(User, null=True, on_delete=models.SET_NULL)
def __str__(self):
return self.name
Writing request and response serializers
Now we are ready to implement the serializers. We are going to write:
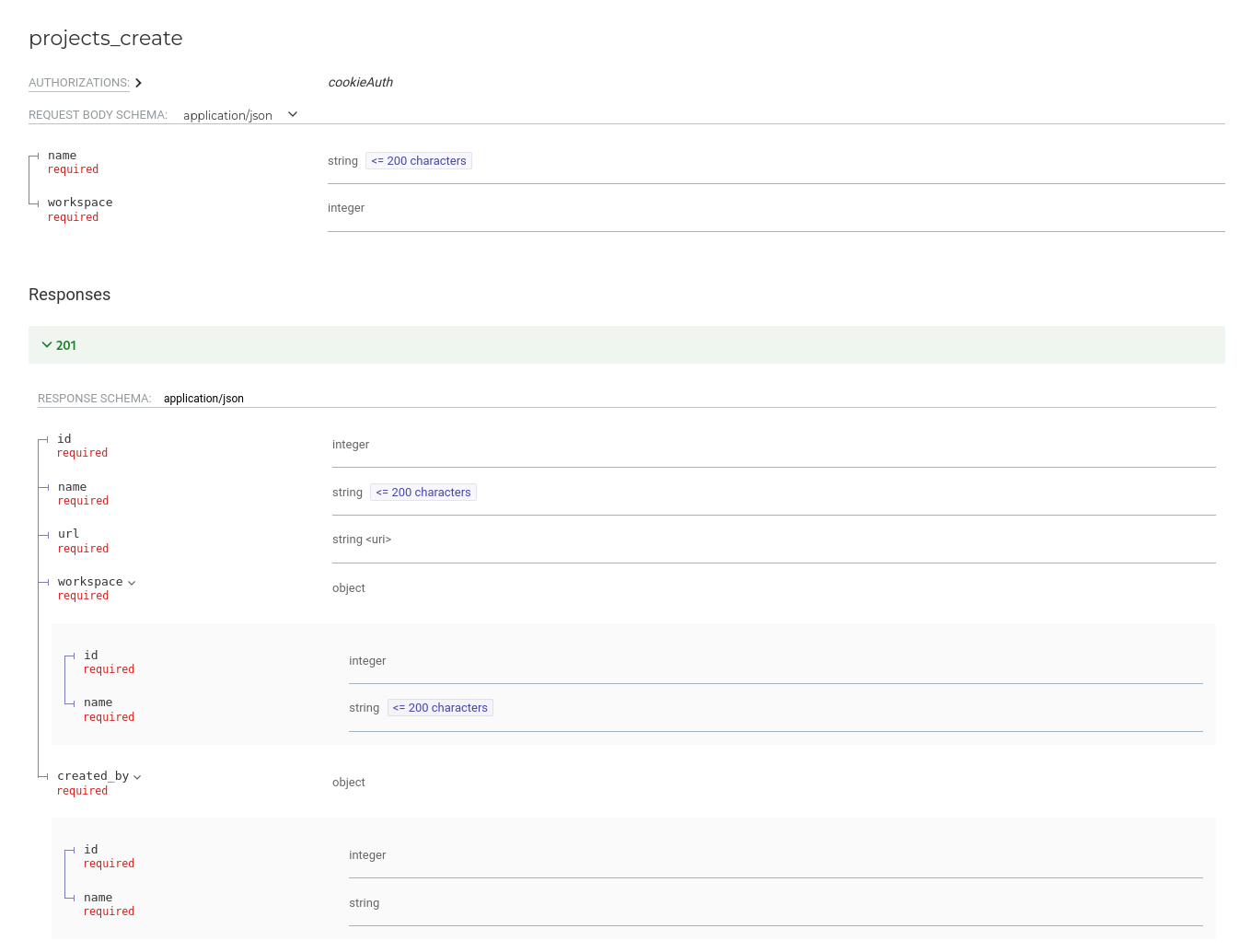
CreatedBySerializerwhich will be used in response serializers to provide information about the user that created the resource.WorkspaceMinimalSerializerwhich will be used in theProjectResponseSerializerto provide information about the assigned workspace without the need to make an additional request.ProjectResponseSerializerwhich will be our response serializers for theProjectmodel.ProjectSerializerwhich will be used in theModelViewSetlater on.
The request serializer ProjectSerializer will handle both incoming data and delegating its own output to the response serializer:
from rest_framework import serializers
from .models import User, Project, Workspace
class CreatedBySerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ("id", "name")
class WorkspaceMinimalSerializer(serializers.ModelSerializer):
class Meta:
model = Workspace
fields = ("id", "name")
class ProjectResponseSerializer(serializers.ModelSerializer):
workspace = WorkspaceMinimalSerializer(read_only=True)
url = serializers.HyperlinkedIdentityField(
view_name="projects-detail",
lookup_field="pk",
)
created_by = CreatedBySerializer(read_only=True)
class Meta:
model = Project
fields = ("id", "name", "url", "workspace", "created_by")
class ProjectSerializer(serializers.ModelSerializer):
class Meta:
model = Project
fields = ("id", "name", "workspace")
def to_representation(self, data):
return ProjectResponseSerializer(context=self.context).to_representation(data)
The key part here is the to_representation() method on the request serializer that is overridden to change its output. We can instantiate our response serializer here (passing the context), and returning the result of to_representation() of ProjectResponseSerializer. We have effectively delegated the responsibility to a different serializer.
Writing ModelViewSets
Since the combined ProjectSerializer handles both requests and responses, it is enough to specify this one serializer in ModelViewSet:
from rest_framework.viewsets import ModelViewSet
from .models import Project
from .serializers import ProjectSerializer
class ProjectViewSet(ModelViewSet):
queryset = Project.objects.all()
serializer_class = ProjectSerializer
As a result, we have achieved different schema for input and output serialization.
OpenAPI documentation
The only problem left is how to correctly document the endpoints now with drf-spectacular as it would automatically generate the schema just from ProjectSerializer. We need to manually annotate the ModelViewSet actions with @extend_schema decorator.
To save ourselves from a lot of typing and convoluted code, let’s implement a helper class decorator that will do it for us:
from drf_spectacular.utils import extend_schema, extend_schema_view
def response_schema(**kwargs):
def decorator(view):
extend_schema_view(
list=extend_schema(responses={200: kwargs['serializer']}),
retrieve=extend_schema(responses={200: kwargs['serializer']}),
create=extend_schema(responses={201: kwargs['serializer']}),
update=extend_schema(responses={200: kwargs['serializer']}),
partial_update=extend_schema(responses={200: kwargs['serializer']})
)(view)
return view
return decorator
The response_schema is a class decorator that will apply additional documentation based on a provided serializer keyword argument.
With such a handy decorator, instructing drf-spectacular to output documentation based on the response serializer for responses is now trivial:
from rest_framework.viewsets import ModelViewSet
from .models import Project
from .serializers import ProjectSerializer
@response_schema(serializer=ProjectResponseSerializer)
class ProjectViewSet(ModelViewSet):
serializer_class = ProjectSerializer
def get_queryset(self):
return Project.objects.select_related("workspace", "created_by").filter(
created_by=self.request.user
)
def perform_create(self, serializer):
serializer.save(created_by=self.request.user)
As a reminder, I added an implementation of get_queryset() method to the example as it is necessary to avoid additional queries when referencing related models (we need to fetch the workspace and created_by attributes of the Project model) on retrieval.
Combination of approaches
If you don’t like the idea that generating a response requires the initialization of two serialization objects, you can combine this approach with the one that we saw at the beginning (the use of the get_serializer_class). If used, all read-only actions could skip ProjectSerializer and use ProjectResponseSerializer directly.
Fin
And that’s really it! Let me know what you think on X @stribny.
Last updated on 17.6.2023.